方法
ArcGIS Pro での重複する値、または一意の値の特定
サマリー
属性テーブルには通常、共通の値と一意の値があるフィールドが含まれています。 そのため、重複する値を特定してレイヤー グループを作成するか、一意の値を特定してフィーチャを隔離する必要がある場合があります。
手順
重複する値を特定するには以下の 4 つの方法があります。
同一値を持つレコードの検出 (Find Identical) ツール を使用する
[同一値を持つレコードの検出 (Find Identical)] ツール は新しいスタンドアロン テーブルを作成します。 このツールは、フィーチャの ObjectID を特定して 2 つの列を作成します。その 1 つには選択したフィーチャの ObjectID の値が含まれており、もう 1 つの列には同一または一意のフィーチャをマークする数字が含まれています。 同一のレコードには同じ FEAT_SEQ 値があるのに対して、同一でないレコードには連番の値があります。 FEAT_SEQ 値は入力レコードの ID とは関連がありません。 詳細については、「ArcGIS Pro: 同一値を持つレコードの検出 (データ管理)」をご参照ください。
フィールド演算関数を使用する
isDuplicate() Python パーサー関数は新しいフィールドにデータを入力して、特定の値を割り当てることで重複する、または一意の値を特定できます。 たとえば、一意の値と複数の値のなかの最初の値には 0 が入力され、重複するすべての値は 1 の値でマークされます。 以下の手順では、この目的のために関数を適用する方法を説明します。
- Short または Long 整数データ タイプがある新しいフィールドを作成します。 詳細については、「ArcGIS Pro: 既存のテーブルへのデータの追加」をご参照ください。
- 新しいフィールドの見出しを右クリックし、[フィールド演算] を選択します。
- [フィールド演算] ウィンドウで適切なパラメーターが選択されていること、および [式の種類] が [Python 3] に設定されていることを確認します。
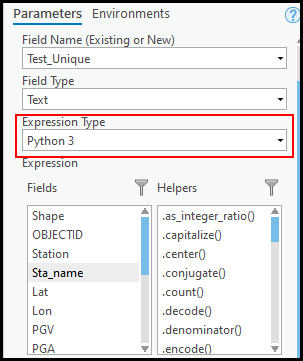
- 式テキスト ボックスに以下のスクリプトを挿入します。
isDuplicate(!Field_Name_To_Verify!)
- [コード ブロック] テキスト ボックスに以下のスクリプトを挿入します。
uniqueList = [] def isDuplicate(inValue): if inValue in uniqueList: return 1 else: uniqueList.append(inValue) return 0
スタンドアロン Python スクリプトを使用する
このスクリプトは新しいフィールドを作成して、重複する値の数をフィールドに入力します。
- 必要なモジュールをインポートします。
import arcpy
- 目的のワークスペース、フィーチャ、入力フィールド、出力フィールドの各パラメーターを指定します。
arcpy.env.workspace=r"D:\test.gdb" infeature="sample_feature" field_in="sample_field" field_out="COUNT_"+field_in arcpy.AddField_management(infeature,field_out,"SHORT")
- 選択したフィールドの値をすべて含むリストを作成します。
lista=[] cursor1=arcpy.SearchCursor(infeature) for row in cursor1: i=row.getValue(field_in) lista.append(i) del cursor1, row
- 重複する値の数を出力フィールドに入力します。
cursor2=arcpy.UpdateCursor(infeature) for row in cursor2: i=row.getValue(field_in) occ=lista.count(i) row.setValue(field_out,occ) cursor2.updateRow(row) del cursor2, row print ("Done.")
以下に、完全なコードを示します。
import arcpy arcpy.env.workspace=r"D:\test.gdb" infeature="sample_feature" field_in="sample_field" field_out="COUNT_"+field_in arcpy.AddField_management(infeature,field_out,"SHORT") lista=[] cursor1=arcpy.SearchCursor(infeature) for row in cursor1: i=row.getValue(field_in) lista.append(i) del cursor1, row cursor2=arcpy.UpdateCursor(infeature) for row in cursor2: i=row.getValue(field_in) occ=lista.count(i) row.setValue(field_out,occ) cursor2.updateRow(row) del cursor2, row print ("Done.")
[要約統計量 (Summary Statistics)] ツールを使用してテーブルを結合する
- [要約統計量 (Summary Statistics)] ツールを実行します。
- [入力レイヤー] (同一のフィーチャまたはレコードがあるターゲット レイヤー) と [出力テーブル] を指定します。
- [統計情報フィールド] で数値の一意の ID フィールドを指定します。 シェープファイルの場合は FID フィールドを選択します。フィーチャクラスの場合は OBJECTID フィールドを選択します。 Pads_DB_PadNumText は以下の例では数値の一意のフィールドです。 [統計の種類] で [最小] を選択します。
- 値を比較して同一のレコードを特定する目的のフィールドを [ケース フィールド ] で選択します。
- ツールを実行して新しいテーブルを作成します。
![[要約統計量 (Summary Statistics)] ツールの画像](https://s3-us-west-2.amazonaws.com/ist-app-support-files/000023355/00N39000003LL2C-0EM5x000001kAeM.png)
- ターゲット レイヤーを右クリックして [結合とリレート] → [テーブルの結合] の順にクリックします。
- 目的のフィールドとして [レイヤー、テーブル ビューのキーとなるフィールド] を選択します。
- [結合テーブル] で、手順 5 で作成したテーブルを選択します。
- [結合先のキーとなるフィールド] を指定してツールを実行します。 結合したテーブルの目的のフィールドと頻度フィールドに重複レコードの情報が表示されます。 テーブルの結合で数値の一意のフィールドを選択すると、出力結合テーブルには一意のレコードだけが表示されます。
![[テーブルの結合] ウィンドウの画像](https://s3-us-west-2.amazonaws.com/ist-app-support-files/000023355/00N39000003LL2C-0EM5x000001kAeR.png)
記事 ID: 000023355
AI によるサポートを受ける
Esri サポート AI チャットボットを使用して問題を迅速に解決します。


関連情報
このトピックについてさらに調べる
Search for related information
Find training related to this topic
Explore ideas and give feedback
ArcGIS エキスパートのサポートを受ける
今すぐチャットを開始