PROCÉDURE
identifier les valeurs uniques et en double dans ArcGIS Pro
Résumé
Il est rare qu'une table attributaire contienne des champs avec des valeurs communes et des valeurs uniques. Par conséquent, il arrive de devoir identifier les valeurs en double pour créer un groupe parmi les couches ou pour identifier les valeurs uniques et isoler l'entité.
Procédure
Il y a quatre façons d'identifier les doublons :
À l'aide de l'outil Rechercher les doublons
L'outil Rechercher les doublons crée une nouvelle table autonome. Il identifie l'ObjectID d'une entité et crée deux colonnes, l'une avec l'ObjectID de l'entité sélectionnée, l'autre avec des numéros pour signaler une entité unique ou en double. Les enregistrements identiques (doublons) ont la même valeur FEAT_SEQ, tandis que les enregistrements non identiques ont une valeur séquentielle. Les valeurs FEAT_SEQ n'ont pas de lien avec les ID des enregistrements en entrée. Pour plus d'informations, reportez-vous à l'article Arc GIS Pro : Rechercher des doublons (Gestion des données).
À l'aide de la fonction Calculate Field (Calculer un champ)
La fonction de l'analyseur Python isDuplicate() peut renseigner un nouveau champ pour identifier une valeur comme double ou unique en lui affectant une valeur spécifique. Par exemple, les valeurs uniques et la première occurrence de plusieurs valeurs sont renseignées par 0, tandis que toutes les valeurs en double sont signalées par la valeur 1. Les étapes suivantes décrivent comment appliquer la fonction dans ce but :
- Créez un nouveau champ dans le type de données d'entier Short (Court) ou Long. Pour plus d'informations, reportez-vous à l'article Arc GIS Pro : Ajouter des données à une table existante.
- Cliquez avec le bouton droit sur l’en-tête du nouveau champ et sélectionnez Calculate Field (Calculer un champ).
- Dans la fenêtre Calculate Field (Calculer un champ), vérifiez que les bons paramètres sont sélectionnés et que le champ Expression Type (Type d’expression) a pour valeur Python 3.
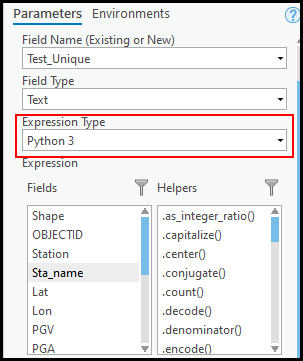
- Dans la zone de texte l’expression, insérez le script suivant :
isDuplicate(!Field_Name_To_Verify!)
- Dans la zone de texte Code Block (Bloc de code), insérez le script suivant :
uniqueList = [] def isDuplicate(inValue): if inValue in uniqueList: return 1 else: uniqueList.append(inValue) return 0
À l'aide d'un script Python autonome
Ce script crée un nouveau champ et le renseigne avec le nombre de valeurs en double.
- Importez le module nécessaire.
import arcpy
- Indiquez les paramètres d'espace de travail, d'entité, de champ en entrée et de champ en sortie souhaités.
arcpy.env.workspace=r"D:\test.gdb" infeature="sample_feature" field_in="sample_field" field_out="COUNT_"+field_in arcpy.AddField_management(infeature,field_out,"SHORT")
- Créez une liste contenant toutes les valeurs dans le champ sélectionné.
lista=[] cursor1=arcpy.SearchCursor(infeature) for row in cursor1: i=row.getValue(field_in) lista.append(i) del cursor1, row
- Renseignez le champ en sortie avec le nombre de valeurs en double.
cursor2=arcpy.UpdateCursor(infeature) for row in cursor2: i=row.getValue(field_in) occ=lista.count(i) row.setValue(field_out,occ) cursor2.updateRow(row) del cursor2, row print ("Done.")
Voici le code complet :
import arcpy arcpy.env.workspace=r"D:\test.gdb" infeature="sample_feature" field_in="sample_field" field_out="COUNT_"+field_in arcpy.AddField_management(infeature,field_out,"SHORT") lista=[] cursor1=arcpy.SearchCursor(infeature) for row in cursor1: i=row.getValue(field_in) lista.append(i) del cursor1, row cursor2=arcpy.UpdateCursor(infeature) for row in cursor2: i=row.getValue(field_in) occ=lista.count(i) row.setValue(field_out,occ) cursor2.updateRow(row) del cursor2, row print ("Done.")
À l'aide de l'outil Résumés statistiques et d'une jointure de table
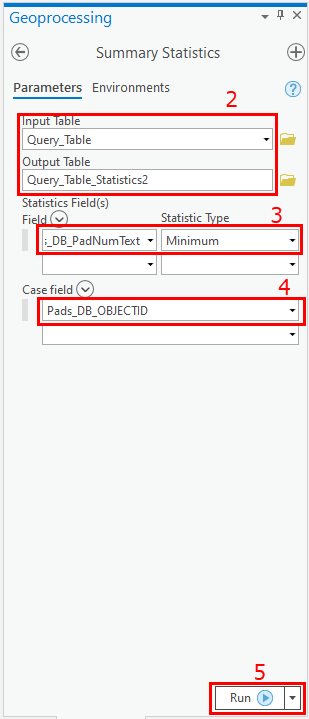
- Exécutez l'outil Résumés statistiques.
- Indiquez la Input Layer (Couche en entrée) (couche cible avec des enregistrements ou des entités identiques) et la Output Table (Table en sortie).
- Dans le Statistics Field (Champ de statistiques), indiquez le champ ID unique numérique. S'il s'agit d'un shapefile, sélectionnez le champ FID ; s'il s'agit d'une classe d'entités, sélectionnez le champ OBJECTID. Dans l'exemple ci-dessous, 'Pads_DB_PadNumText' est un champ unique numérique. Sélectionnez Minimum comme Statistic Type (Type de statistique).
- Dans le champ Case Fields (Champ de récapitulation), sélectionnez le champ pour lequel vous voulez que les valeurs soient comparées pour rechercher des enregistrements identiques.
- Exécutez l'outil pour créer une nouvelle table.
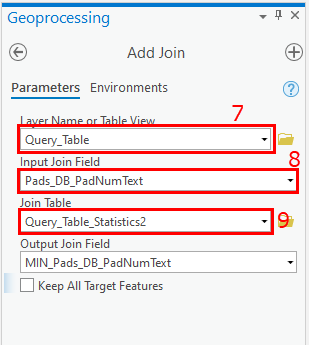
- Cliquez avec le bouton droit sur la couche cible et cliquez sur Joins and Relates (Jointures et relations) puis sur Add Join (Ajouter une jointure).
- Sélectionnez Input Join Field (Champ de jointure en entrée) comme champ souhaité.
- Pour Join Table (Table de jointure), sélectionnez la table créée à l'étape 5.
- Renseignez le champ Output Join Field (Champ de jointure en sortie) et exécutez l'outil. Le champ souhaité et le champ de fréquence de la table jointe fournissent des informations aux enregistrements en double. Si le champ unique numérique est sélectionné pour la jointure des tables, la table jointe en sortie affiche uniquement les enregistrements uniques.
ID d’article: 000023355
Obtenez de l'aide avec l'IA
Résolvez rapidement votre problème avec le chatbot Esri Support AI.


Informations associées
En savoir plus sur ce sujet
Search for related information
Find training related to this topic
Explore ideas and give feedback
Obtenir de l’aide auprès des experts ArcGIS
Commencez à discuter maintenant