HOW TO
Identify duplicate or unique values in ArcGIS Pro
Summary
It is usual for an attribute table to contain fields with common values and unique values. So, it is sometimes necessary to identify duplicate values to create a group among layers, or to identify unique values to isolate the feature.
Procedure
There are four different ways to identify duplicate values:
Using the Find Identical tool
The Find Identical tool creates a new stand-alone table. The tool identifies the ObjectID of a feature and creates two columns, one containing the ObjectID value of the selected feature and the other containing numbers to mark an identical or unique feature. Identical records have the same FEAT_SEQ value, while non-identical records have sequential value. FEAT_SEQ values have no relationship to IDs of input records. Refer to ArcGIS Pro: Find Identical (Data Management) for more information.
Using the Calculate Field function
The isDuplicate() Python parser function can populate a new field to identify a value as duplicate or unique by assigning a specific value. For example, unique values and the first occurrence of multiple values are populated with 0, and all duplicate values are marked with a value of 1. The following steps describe how to apply the function for this purpose:
- Create a new field with Short or Long integer data type. Refer to ArcGIS Pro: Add data to an existing table for more information.
- Right-click the header of the new field, and select Calculate Field.
- In the Calculate Field pane, ensure the right parameters are selected, and the Expression Type is set to Python 3.
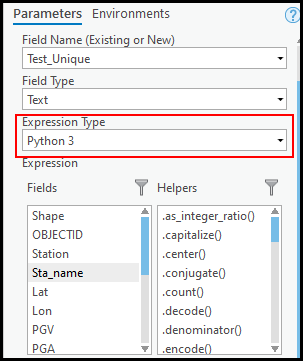
- In the expression text box, insert the following script:
isDuplicate(!Field_Name_To_Verify!)
- In the Code Block text box, insert the following script:
uniqueList = []
def isDuplicate(inValue):
if inValue in uniqueList:
return 1
else:
uniqueList.append(inValue)
return 0
Using a stand-alone Python script
The script creates a new field and populates the field with the number of duplicate values.
- Import the necessary module.
import arcpy
- Specify the desired workspace, feature, input field and the output field parameters.
arcpy.env.workspace=r"D:\test.gdb" infeature="sample_feature" field_in="sample_field" field_out="COUNT_"+field_in arcpy.AddField_management(infeature,field_out,"SHORT")
- Create a list containing all the values in the selected field.
lista=[]
cursor1=arcpy.SearchCursor(infeature)
for row in cursor1:
i=row.getValue(field_in)
lista.append(i)
del cursor1, row
- Populate the output field with the number of duplicate values.
cursor2=arcpy.UpdateCursor(infeature)
for row in cursor2:
i=row.getValue(field_in)
occ=lista.count(i)
row.setValue(field_out,occ)
cursor2.updateRow(row)
del cursor2, row
print ("Done.")
The following shows the full code:
import arcpy
arcpy.env.workspace=r"D:\test.gdb"
infeature="sample_feature"
field_in="sample_field"
field_out="COUNT_"+field_in
arcpy.AddField_management(infeature,field_out,"SHORT")
lista=[]
cursor1=arcpy.SearchCursor(infeature)
for row in cursor1:
i=row.getValue(field_in)
lista.append(i)
del cursor1, row
cursor2=arcpy.UpdateCursor(infeature)
for row in cursor2:
i=row.getValue(field_in)
occ=lista.count(i)
row.setValue(field_out,occ)
cursor2.updateRow(row)
del cursor2, row
print ("Done.")
Using the Summary Statistics tool, and joining the table
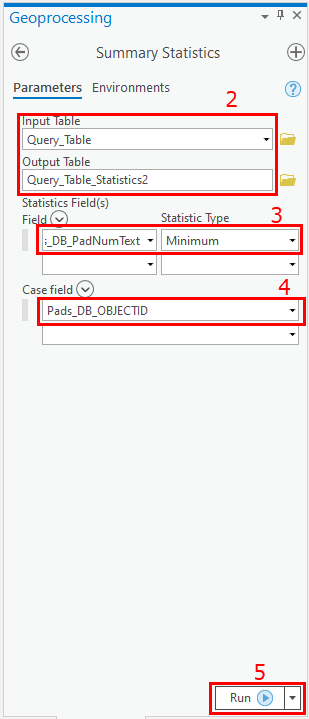
- Run the Summary Statistics tool.
- Specify the Input Layer (the target layer with identical features or records) and Output Table.
- For Statistics Field, specify the numeric unique ID field. If it's a shapefile, select the FID field; if it's a feature class, select the OBJECTID field. The 'Pads_DB_PadNumText' is a numeric unique field in the example below. Select Minimum for Statistic Type.
- Select the desired field wherein the values are compared to find identical records in Case Field.
- Run the tool to create a new table.
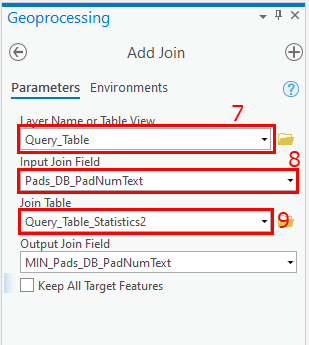
- Right-click the target layer, and click Joins and Relates > Add Join.
- Select Input Join Field as the desired field.
- For Join Table, select the table created in Step 5.
- Specify the Output Join Field, and run the tool. The desired field and frequency field in the joined table provide information on duplicate records. If the numeric unique field is selected for joining the tables, the output joined table shows only unique records.
Article ID: 000023355
- ArcGIS Pro 2 x
Get support with AI
Resolve your issue quickly with the Esri Support AI Chatbot.


Related Information
Discover more on this topic
Search for related information
Find training related to this topic
Explore ideas and give feedback
Get help from ArcGIS experts
Start chatting now